
Part of the project Underwater Computer Vision for Environmental Monitoring
Sea-ing Through Scattered Rays: Revisiting the Image Formation Model for Realistic Underwater Image Generation
Vasiliki Ismiroglou*, Malte Pedersen, Stefan H. Bengtson, Andreas Aakerberg, Thomas B. Moeslund
Joint Workshop on Marine Vision @ ICCV’25
Background
Keeping an eye on what’s happening underwater is critical, but actually getting good data from below the surface is far from easy. One of the biggest challenges is turbidity. That is the particle concentration in water that results in a cloudy appearance and reduced visibility. Turbid water increasingly scatters and absorbs light, making it hard for cameras to capture clear images. As a result, existing work in underwater monitoring often skips the murkiest conditions altogether, leaving gaps in the data. When data is collected in turbid water, it’s tricky to label or annotate because details are hidden and visibility is reduced.
To fill these gaps, research has often turned to synthetic data. Particularly, the image formation model (IFM) has been used to simulate different underwater conditions on existing images. This can help increase the volume and variation of underwater data, which is particularly important for data-hungry deep-learning models.
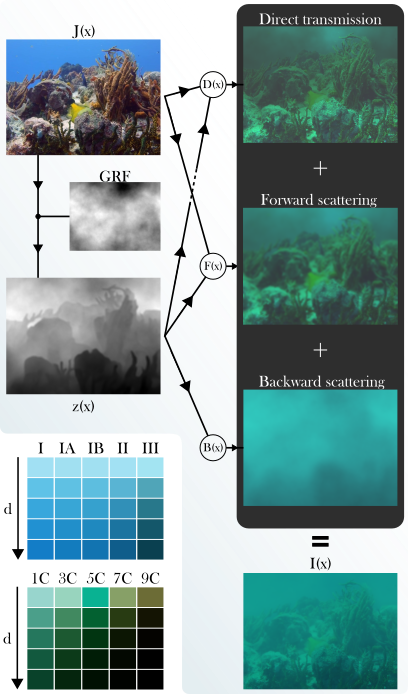
The underwater IFM aims to describe degraded underwater images as a sum of two components:
- Light that reaches the camera without being scattered or absorbed makes up the direct transmission term.
- Light that gets scattered back towards the camera by suspended particles before reaching the scene makes up the backscattering term.
The forward scattering term, that corresponds to light scattered at small angles in its path to the camera, while remaining in the field of view of the lens, is commonly ignored.
Method
Omitting the forward scattering term heavily overestimates light attenuation, especially as scattering coefficients increase, producing visually artificial images. Therefore, in this work, we re-introduce forward scattering, while additionally proposing 2D Gaussian Random Fields (GRF) as a way of simulating medium inhomogeneity when synthesizing data.
Our pipeline is outlined in Figure 1. A clean underwater image is passed through a monocular depth estimator, in this case DepthAnythingv2 [1], to extract scene geometry information. A 2D GRF is generated, and multiplied with the exponents of the image formation model, simulating inhomogeneities in the medium. Using attenuation coefficients for the target water type, along with the input image and its depth map, the direct transmission, forward scattering and backscattering terms are calculated, producing the final degraded image.
The forward scattering term is a slightly blurred version of the direct transmission, and as such, contains information of the original scene. Consequently, the effective attenuation of our proposed pipeline is reduced compared to the original model.
The BUCKET dataset
In order to compare synthesized data with real turbid conditions, we collected the Baseline for Underwater Conditions in Known Environments and Turbidity (BUCKET) dataset. It contains images of statics scenes, with different degrees of induced turbidity, produced by the addition of milk and clay in water.







Figure 2: On the left, the data collection setup. On the right, example images.
Results
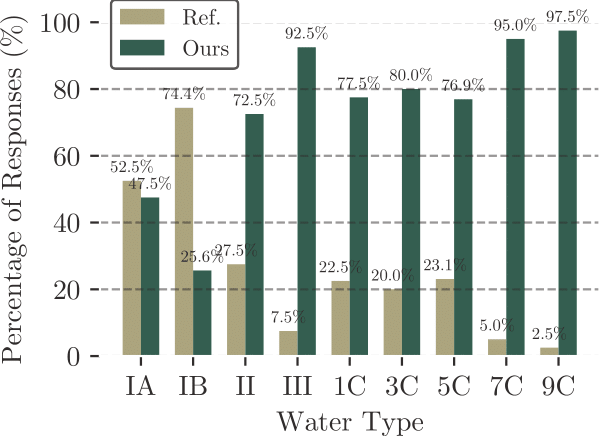
We qualitatively compared both our pipeline and the original model using the BUCKET data. We additionally generated synthesized images of real underwater scenes and collected survey responses on image realism. Our pipeline results in visually realistic underwater images, even under high turbidity conditions, and had an 82.5% selection rate by survey participants.

























Citation
@misc{ismiroglou2025seaingscatteredraysrevisiting,
title={Sea-ing Through Scattered Rays: Revisiting the Image Formation Model for Realistic Underwater Image Generation},
author={Vasiliki Ismiroglou and Malte Pedersen and Stefan H. Bengtson and Andreas Aakerberg and Thomas B. Moeslund},
year={2025},
eprint={2509.15011},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2509.15011},
}
References
[1] Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth Anything V2, 2024. arXiv:2406.09414
