
A part of the project: Automated Sewer Inspection Robot
Multi-Scale Hybrid Vision Transformer and Sinkhorn Tokenizer
for Sewer Defect Classification
Joakim Bruslund Haurum, Meysam Madadi, Sergio Escalera, and Thomas B. Moeslund
Automation in Construction
Paper | Code | Models
(code and model weights will be released before mid December)
Introduction
This is the project page for the Multi-Scale Hybrid Vision Transformer (MSHViT) and the Sinkhorn Tokenizer, a novel cross CNN and ViT architecture and clustering-based tokenizers, which increases sewer defect classification performance by allowing for non-local interactions. A crucial part of image classification consists of capturing non-local spatial semantics of image content. This paper describes the multi-scale hybrid vision transformer (MSHViT), an extension of the classical convolutional neural network (CNN) backbone, for multi-label sewer defect classification. To better model spatial semantics in the images, features are aggregated at different scales non-locally through the use of a lightweight vision transformer, and a smaller set of tokens was produced through a novel Sinkhorn clustering-based tokenizer using distinct cluster centers. The proposed MSHViT and Sinkhorn tokenizer were evaluated on the Sewer-ML multi-label sewer defect classification dataset, showing consistent performance improvements of up to 2.53 percentage points.
Multi-Scale Hybrid Vision Transformer and Sinkhorn Tokenizer
Since its adoption in 2017, the Convolutional Neural Network (CNN) has been the method of choice within the automated sewer inspection domain. However, while CNNs are good at modeling local interactions, they are not struggle with modelling non-local interactions such as when there is simultaneously a displaced joint and intruding roots in an image but in opposite corners. We therefore propose the Multi-Scale Hybrid Vision Transformer (MSHViT), where a Vision Transformer (ViT) is appended at different stages of a CNN backbone for non-local aggregation of features and cross-scale propagation of features. We also introduce the Sinkhorn tokenizer, a clustering-based tokenizer to replace the simple patch based tokenizer in ViTs and act as another source of non-local spatial semantics.
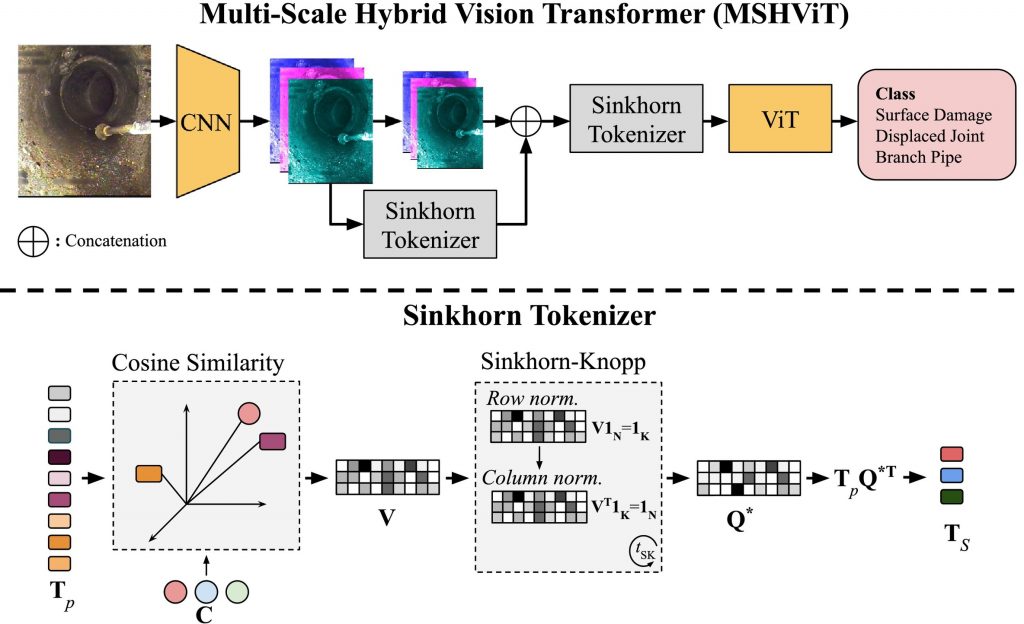
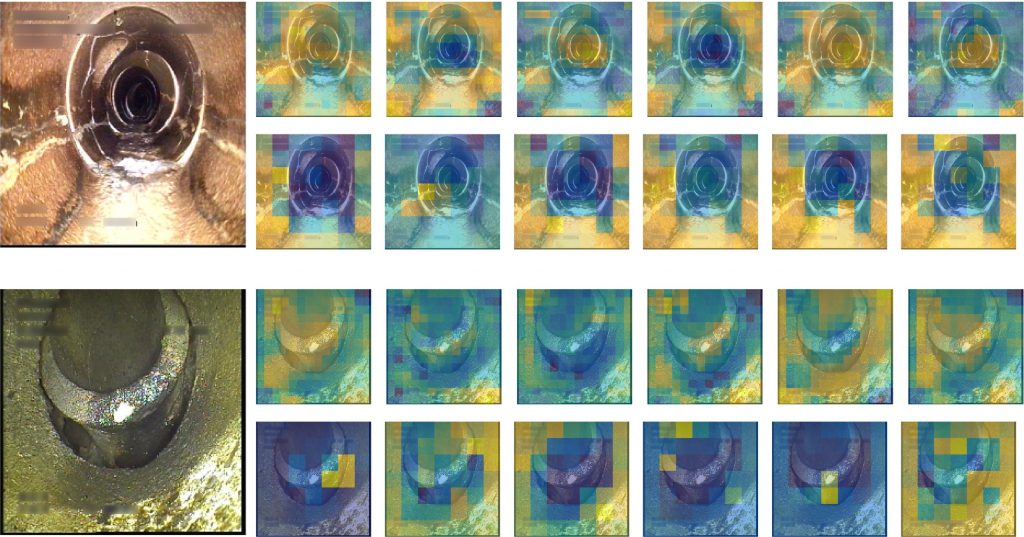
We demonstrate that the Sinkhorn tokenizer successfully cluster the CNN features, which are expected to have a high amount of redundant information due to successively applying overlapping convolutional filters and pooling layers. These clusters can be used for post hoc visual explanation of the MSHViT model by relating the output predictions to the input image. This makes the automatic classification process less opaque to the sewer inspector, and may help reduce variability in sewer inspections
Results
Using the Sewer-ML sewer defect classification datasetwe compare the proposed MSHViT model with previous sewer classification methods, and Hybrid Vision Transformer like (HViT-Like) methods. We find that the MSHViT outperforms all other models, and matches the performance of the multi-task CT-GAT model, without using aditional tasks or labels. More in-depth results can be found in the paper.
| Model | F2-CIW (Val) | F1-Normal (Val) | F2-CIW (Test) | F1-Normal (Test) |
| Benchmark | 55.36 | 91.32 | 55.11 | 90.94 |
| HViT | 59.87 | 92.41 | 57.58 | 91.99 |
| BotNet-S1 | 61.62 | 92.92 | 59.69 | 92.49 |
| CT-GAT | 61.70 | 91.94 | 60.57 | 91.61 |
| MSHViT | 61.68 | 92.44 | 60.11 | 92.11 |
Citation
@article{Haurum_2022_AiC,
author = {Haurum, Joakim Bruslund and Madadi, Meysam and Escalera, Sergio and Moeslund, Thomas B.},
title = {Multi-scale hybrid vision transformer and Sinkhorn tokenizer for sewer defect classification},
journal = {Automation in Construction},
volume = {144},
pages = {104614},
year = {2022},
issn = {0926-5805}
}
