
A part of the project: Automated Sewer Inspection Robot
Sewer-ML:
A Multi-Label Sewer Defect Classification Dataset and Benchmark
Joakim Bruslund Haurum and Thomas B. Moeslund
CVPR 2021
Paper (ArXiv) | Paper (CVF) | Code | Dataset| Models| Leaderboard
Introduction
This is the project page for Sewer-ML, the first publicly available sewer defect dataset. The sewerage infrastructure is one of the most costly infrastructures in modern society. Sewer pipes are currently manually inspected by licensed professionals. This is a time consuming process, therefore it is infeasible to inspect all pipes regularly. By automating the sewer pipe inspection process, the sewerage infrastructure can be better managed due to an increase in completed inspections.
With the publication of Sewer-ML, we hope that we can spark the interest in the field such that solutions to the difficulty problem of sewer defect classification can be further developed.
Dataset
| Type | Training | Validation | Test | Total |
|---|---|---|---|---|
| Normal | 552,820 | 68,681 | 69,221 | 690,722 |
| Defective | 487,309 | 61,365 | 60,805 | 609,479 |
| Total | 1,040,129 | 130,046 | 130,026 | 1,300,201 |
The Sewer-ML dataset contains 1.3 million images, from 75,618 videos collected from three Danish water utility companies over nine years. All videos have been annotated by licensed sewer inspectors following the Danish sewer inspection standard, Fotomanualen. This leads to consistent and reliable annotations, and a total of 17 annotated defect classes.
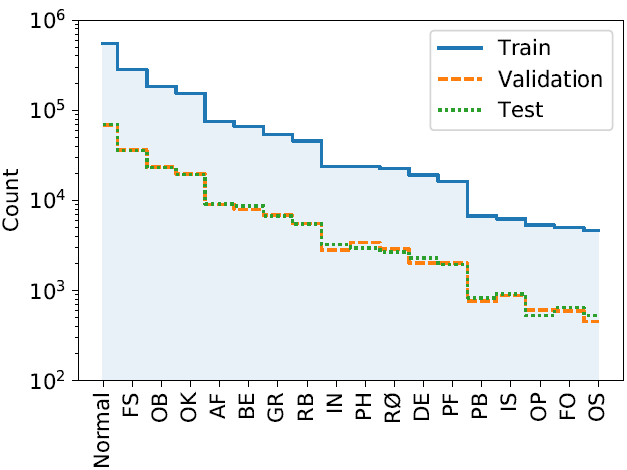
The image annotations have been extracted based on a set of heuristic rules, enabling multi-label classification methods, and split into separate training, validation and test splits. The dataset consists of a nearly 50-50% of images with either no defect or at least one defect class present. Unlike prior sewer inspection datasets, we do not manually balance the defect classes. Instead we keep all data points such that the dataset is representative of the real life distribution of classes.

Normal Pipe 
DE, PF 
FO, FS
Results
There has traditionally been no consensus on how to compare sewer defect classification methods. Therefore, we present a novel class importance weighted (CIW) F2-Score for quantifying the defect classification performance based on their economic impact for the sewer pipe owners, called F2-CIW. However, as pipes with no defects do not have a class importance weight, a large part of the dataset is not considered in the F2-CIW measure. We propose using the common F1-score for evaluating the performance on correctly identifying images with no defects.
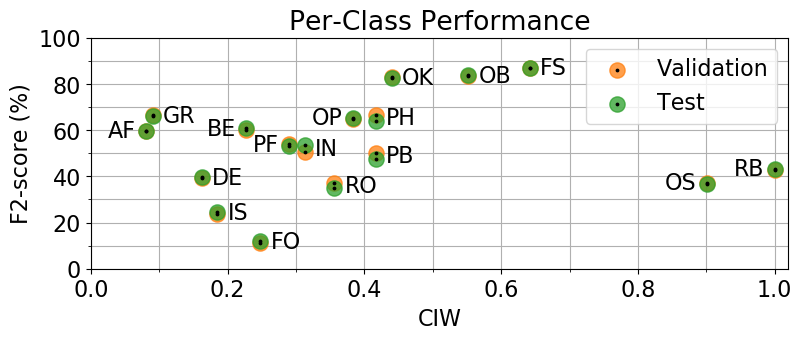
We compared 12 different multi-label classification methods: six state-of-the-art methods from the sewer defect classification domain, and six state-of-the-art methods from the general multi-label classification domain. We find that the best performance was achieved through a combination of two methods using a small CNN for an initial binary defect classification step, followed by a larger CNN, TResNet-L, to perform the multi-label classification step. This results in a F2-CIW of 55.11% and F1-Normal of 90.94%. From the per-class results we notice that the defect classes with the largest economic impact, OS and RB, are also some of the currently worst recognized defects. This indicates that there is still ample room for improvement, and that the sewer defect classification problem is not yet solved.
Citation
@InProceedings{Haurum_2021_CVPR,
author = {Haurum, Joakim Bruslund and Moeslund, Thomas B.},
title = {Sewer-ML: A Multi-Label Sewer Defect Classification Dataset and Benchmark},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2021},
pages = {13456-13467}
}
